Process ები, CPU Virtualization, IPC და Thread ები A.K.A ნაკადები
შესავალი

იმის მიუხედავად, რომ ჩემი ყოველდღიური Software Engineer ის ცხოვრება iOS სამყაროში მიმდინარეობს, ოდითგანვე მაინტერესებდა სისტემური პროგრამირება და ოპერაციული სისტემები, ხოლო ბოლო თვეების განმავლობაში ჩემს პროექტებს არსებითად დიდი კავშირი აქვთ low-level თან და ფუნდამენტალურ საკითხებთან, რის გამოც მომიწია ბევრი საინტერესო საკითხების წაკითხვა, გაცნობა და შესწავლა. შემდეგ დავაკვირდი, რომ საკმაოდ კარგი კლას-გარეშე სავარჯიშო იყო, რისი მეშვეობითაც ჩემს domain ში ბევრად უფრო პროდუქტიული და თავდაჯერებულიც ვხდებოდი.
დეველოპერები ყოველდღიურად ვსხედვართ ჩვენს კომპიუტერებთან, framework ებთან და ვიყენებთ ხელსაწყოებს, რომლებიც არ გვესმის როგორ მუშაობს. ვსწავლობთ მხოლოდ აბსტრაქციებს, მაღალი დონის ხელსაწყოებს და ხანდახან ეს ძალიან გვაშორებს რეალობისგან, რომელიც ძალიან საინტერესოა.
კონკურენტ-უნარიან სამყაროში ხშირად ვხედავთ რომ არსებობენ top level და avarage level დეველოპერები. მე მჯერა, რომ ფუნდამენტალური საკითხების, თუნდაც ზედაპირულად high-level პერსპექტივიდან ცოდნა ბევრად უკეთეს დეველოპერებად გვაყალიბებს ჩვენს ყოველდღიურ საქმიანობაში, რომლებიც ასე გვიყვარს და გვაინტერესებს.
პროგრამირების, სისტემების, ჩვენი საკუთარი framework ების და პლატფორმების ფუნდამენტალური ცოდნა, გაგება თუ როგორ მუშაობს ყველაფერი ფარდის უკან, მჯერა რომ ერთ-ერთი უმთავრესი skill ია დღეს იმ ბაზარზე, სადაც ვმოღვაწეობთ.
სტატიაში გაგიზიარებთ ჩემს მწირ ცოდნას Process, CPU Virtualization, IPC და User/Kernel level Thread ებზე.
Process
Process — ი უნდა წარმოვიდგინოთ, რომ არის ისეთი dynamic entity, რომელიც სხვადასხვა დავალებას ასრულებს ოპერაციულ სისტემაში და ასევე ცვალებადია მისი მიმდინარეობის დროს.
ხშირად პროგრამა და პროცესი სინონიმები გვგონია, თუმცა ესე არაა. პროგრამა არის მანქანური კოდის ინსტრუქცია, რომელიც დისკზე გვაქვს შენახული და პასიური entity ია. როდესაც პროგრამას ჩვენს სისტემაზე ვუშვებთ, იქმნება პროცესი რომელიც ამ კონკრეტული პროგრამის execution ის მიმდინარეობაა.
პროგრამა როგორც ასეთი უსიცოცხლო ობიექტია, რომელიც დისკზე ცოცხლობს. როდესაც მას ვუშვებთ ჩვენი OS ი აკეთებს ინიციალიზაციას ახალი პროცესის, რომელიც ჩვენს არჩეულ პროგრამას უშვებს პროცესის სახით.
Process-ს ყოველთვის ყავს Parent process ი და შესაძლებელია ყავდეს ასევე child process ი. ყველა child პროცესი იქმნება parent პროცესიდან გამომდინარე, ანუ ოპერაციული სისტემა ქმნის ახალ პროცეს parent პროცესიდან აკოპირებს მთლიან სტეიტს და ანიჭებს ახალ PID(process identifier) ს.
Linux ის სისტემაში მთავარი პროცესი არის init-ი, ხოლო სხვა ყველა დანარჩენი არის init ის შვილობილი პროცესები.

პროცესები Circular Double linked list ში ინახება. Linked list ის root ი რა თქმა უნდა იქნება init პროცესი, რომელიც kernel ში task_struct ის მონაცემთა სტრუქტურის სახით გვხვდება.

მნიშვნელოვანია ასევე ვისაუბროთ Process ების სტეიტებზე.
Running
პროცესი ან არის გაშვებულ რეჟიმში ან ელოდება გაშვებას. Running სტეიტი ზუსტად ამას გვეუბნება, პროცესი ლოდინის რეჟიმშია თუ უკვე გაშვებულია და იყენებს hardware ის რესურსს.
Waiting
ამ სტეიტში პროცესი ელოდება რაიმე event ს ან რაიმე resource ის გამოყოფას სანამ გაეშვება. Linux ის სამყაროში waiting process ებს ორ ტიპად ყოფენ.
interruptible uninterruptible
interruptible ტიპის waiting process ი შეიძლება მართული იყოს სხვადასხვა სიგნალების მიერ, მეორეს მხრივ uninterruptible პროცესი პირდაპირ დამოკიდებულია hardware ის სხვადასხვა condition ზე, რაც შეუძლებელს ხდის მის შეჩერებას ან რაიმე სხვა გზის გავლენის მოხდენას.
Stopped
პროცესი გაჩერდა, რაიმე სიგნალის შემდეგ. მაგალითისთვის, როდესაც თქვენს დაწერილ პროგრამებს ადებაგებთ, თქვენი არსებული პროგრამა, რომელიც სისტემაში პროცესადაა გაშვებული Stopped state ში გადადის, და ელოდება სიგნალს რომ ისევ Running state ში გადავიდეს.
Zombie
Zombie პროცესებს ისეთ პროცესებს ვეძახით, რომელიც რაღაცა მიზეზის გამო ისევ არიან ჯერ task_struct ის Linked list ში, მაგრამ მკვდარი პროცესია და არანაირ რესურსს არ იყენებს hardware ის.
ეს ყველა state ყველაზე მეტად პროცესების scheduler ს ჭირდება, რომ სამართლიანად გადაწყვიტოს თუ რომელ process ი იმსახურებს სისტემაში გაშვებას და ყურადღების მიქცევას.
ასევე ყველა პროცესს აქვს უნიკალური identifier ი, რომელსაც pid(process identifier)’ს ვეძახით. მაგალითად ჩემს Macbook ში რომ htop გავუშვა ტერმინალიდან, ესეთ რაღაცას ვნახავთ.
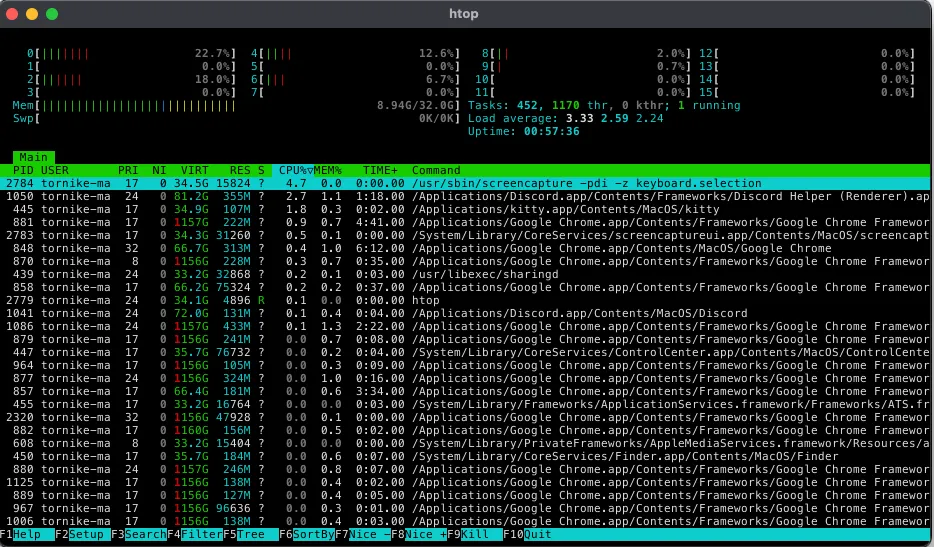
ჩემს screenshot ს თუ დავაკვირდებით ბევრ საინტერესო დეტალს შევამჩნევთ.
- სისტემაში გაშვებულ პროცესებს
- PID ები, რომელიც უნიკალურია თითოეული პროცესისთვის
- პროცესის owner ი
და სხვადასხვა მეტა ინფორმაცია memory ზე და CPU ზე.
ყველა პროცესი ერთმანეთისგან პარალელურად მუშაობს და ერთმანეთს ხელს არაფერში არ უშლის.
ასევე საინტერესოა ის ნაწილი სადაც უნდა ვისაუბროთ Memory sharing ზე. პროცესებს საკუთარი თავი ოპერაციული სისტემის ერთადერთი მესაკუთრეები გონიათ, რადგან თითოეული პროცესისთვის გამოიყოფა ცალკე address space — ი, ეს გვაძლევს საშვალებას, რომ თითოეულ პროცესს ქონდეს საკუთარი stack ი და საკუთარი heap ი და I/O (თუ ჯერ არ იცით რაზე გვაქვს საუბარი ამ ბმულს ეწვიეთ დასაწყისისთვის გეყოფათ)
როგორც დასაწყისში ვახსენეთ, პროცესი წარმოადგენს გაშვებულ პროგრამას. იმ მოწყობილებებზე, რომლებსაც ყოველდღიურად ვიყენებთ გაშვებული გვაქვს უამრავი პროცესი პარალელურად, და ისინი იდეალურად მუშაობენ კონკურენტულ გარემოში.
მაგრამ როგორ? ჩვენ ხომ ვიცით რომ CPU’ს რესურსები ულიმიტო არ არის და ის ჩვენ ლიმიტირებულად გვაქვს ინსტრუქტციების შესასრულებლად. რეალურად კი CPU ს რესურსები განაწილებულია ყველა პროცესისთვის CPU virtualization ის წყალობით.
CPU Virtualization
CPU virtualization ი კონცეპტუალურად არის პროცესი სადაც იქმნება ილუზია რომ ჩვენ გვაქვს ბევრი CPU იმ ფაქტის გამორიცხვით რომ ჩვენს მანქანებს მხოლოდ რამოდენიმე აქვთ. თანამედროვე კომპიუტერულ მეცნიერებაში მრავალი ხერხი არსებობს ზემოთ ხსენებულის იმპლემენტაციისთვის. ფუნდამენტალური ტექნიკა ამისთვის არის CPU time sharing.
პრიორიტეტების გადანაწილებას და CPU რესურსის გადანაწილებას სხვადასხვა პროცესებზე OS Scheduler ი წყვიტავს.
time-sharing ი კი არის სიტუაცია, როდესაც process ებს კონკრეტული დრო ეძლევათ რესურსების გამოყენებისთვის. ყველა პროცესი CPU ს რესურსს რაღაც დროის მონაკვეთით იღებს. Scheduler ი უფლებას აძლევს პროცესს რომ X დროის მონაკვეთში გამოიყენოს რესურსები, ამ დროს quantum ს ან time slice ს ვეძახით. თუ პროცეს’ს საკუთარი quantum ი ამოეწურება უკან ბრუნდება ready queue ში და სტეიტიც ეცვლება, ხოლო მის ადგილას ახალი პროცესი მოდის და გადადის running state ში.
Quantum ის გამოთვლა საკმაოდ რთული პროცესია და ხდება ძალიან ფრთხილად, ყოველთვის როცა ოპერაციული სისტემა Scheduling გადაწყვეტილებას იღებს თვითონ Scheduler ი იყენებს პროცესორს. როდესაც სისტემა რამოდენიმე პროცესს ემსახურება Scheduler ს ჭირდება system processing time ი რომ საკუთარი computation ზე იმუშაოს და გადაწყვიტოს თუ რომელი პროცესი გაუშვას და შემდეგ შეუცვალოს მათ სტეიტები. ამ ოპერაციას context switching ი ეწოდება. დროის მონაკვეთს, რომელიც scheduler ს ჭირდება scheduling overhead ი.
თუ გამოთვლილი quanta ზედმეტად მცირეა, ოპერაციულ სისტემას მეთი scheduling ოპერაციები დასჭირდება და უფრო ხშირად, რაც ნიშნავს რომ მთლიანი სისტემის პროცესინგის და რესურსის overhead ი მოხდება. მეორეს მხრივ თუ quanta ძალიან დიდია, მაშინ სხვა პროცესები დიდხანს იცდიან ready queue ში და ამ დროს არსებობს რისკი რომ system ის მომხმარებელმა შეამჩნიოს მწირი რესფონსიულობა.
იმისთვის, რომ პროცესებზე საუბარი რაღაც მხრივ ამოვწუროთ საჭროა ასევე ვისაუბროთ თუ როგორ ამყარებენ კომუნიკაციას ერთმანეთს შორის პროცესები და რა გზები არსებობს ამის მისაღწევად.
Inter-process Communication (IPC)
სხვადასხვა პროცესები, რომლებიც გაშვებულია ერთ მანქანაზე იყენებენ IPC ის ერთმანეთთან საკომუნიკაციოთ.
დღეს სხვადასხვა IPC მექანიზმი არსებობს, მაგრამ ფუნდამენტალურად ყველა იყენებს shared memory ს.
OS ი ალოკაციას უკეთებს რაღაც ოდენობის memory ს სპეციალურად IPC კომუნიკაციისთვის. OS ის და მანქანის ტიპის მიხედვით ამ პროცესს სპეციალური იმპლემენტაცია ჭირდება, რომ shared memory წვდომადი იყოს პროცესებისთვის, რომელიც შესაძლოა სხვადასხვა core ზე ან CPU ზე იყვნენ გაშვებულები.
როდესაც 1 პროცესს უნდა მეორესთვის ინფრომაციის გაგზავნა ან მიღება, ის ეძახის ოპერაციულ სისტემას, რომელიც რაღაც ტიპის LOCK ს აკეთებს კონკრეტულ მემორიზე და შემდეგ ახორციელებს read/write ს. Lock ი პრევენციას უკეთებს კონკურენტულ გარემოში 1 რესურსზე — 2 ან მეტ პარალელურ წვდომას, საწინააღმდეგო შემთხვევაში შესაძლებელია მოხდეს data corruption ი.
მაგალითად Linux ზე ზემოთ აღწერილი პროცესების რეალიზაციისთვის იყენებენ pipe-ებს. Pipe არის high-level მექანიზმი, რომელიც ზემოთ აღწერილს აბსტრაქციას აკეთებს, ის ჩვეულებრივი command ია და პროცესების საკომუნიკაციოდ გამოიყენება. ჩემთვის ცნობილი სულ 2 ტიპის pipe არის.
- named
- unnamed
named pipe ები FIFO პრინციპით მუშაობენ (First in, first out), ესეთი ტიპის pipe ებს შეუძლიათ ინფორმაცია გაცვალონ ისეთ პროცესებს შორის, რომლებიც სხვადასხვა core ზე ან CPU ზე ცოცხლობენ.
unnamed pipe ები კი მხოლოდ მაშინ გამოიყენება, როცა process ები მჭიდროდ არიან ერთმანეთთან დაკავშრებულები, ანუ იყენებენ ერთ CPU ს და რესურსს ზემოთ ხსენებული time sharing ით ინაწილებენ.
Pipe ის შექმნის დროს სისტემა ქმნის file descriptor ს ფაილურ სისტემაში, რომელიც დაკავშირებულია local socket თან. socket ის ერთ მხარეს ინფორმაციის ჩაწერისას მონაცემის კოპირება ხდება memory buffer ში ხოლო ამის შემდეგ სისტემა სიგნალს უგზავნის ყველა ისეთ პროცესს, რომელიც ელოდება ინფორმაციის წაკითხვას ამ სოკეტიდან.
ინფორმაციის მიმოცვლის დროს უკან რა თქმა უნდა უამრავი კომპლექსური დეტალი და ალგორითმი იმალება, მაგრამ ფუნდამენტალურად მაინც ყველაფერი დადის shared memory დან წაკითხვა ან მასში ჩაწერაზე.
რაღაც მხრივ ალბათ ამოვწურეთ ძალიან აბსტრაქტულად process ებზე საუბარი და ეხლა დროა Thread ებზე ანუ ნაკადებზე გადავიდეთ რომელსაც high-level დეველოპერები ასე თუ ისე ვიცნობთ და ვიყენებთ ყოველდღიურად.
Threads A.K.A ნაკადები
იმისთვის, რომ thread ებზე ფუნდამენტალურად ვისაუბროთ, აუცილებელია ოდნავ მაინც გვესმოდეს Process ები, ზუსტად ამის გამო დავიწყე ჩემი სტატია პროცესებზე საუბრით.
Thread ი ერთი პროცესის execution unit ია, რომელიც პროცესის გარეშე ვერ იარსებებს. ერთ პროცესს შეიძლება ქონდეს მრავალი სხვადასხვა thread ი, რომელიც ეხმარება პროცეს პარალელიზმში. პარალელიზმში იგულისხმება სხვადასხვა მანქანური ინსტრუქციის კონკურენტ უნარიან, პარალელურ გარემოში გაშვებას.
Thread ს lightweight პროცესსაც კი ეძახიან. იდეა, როგორც უკვე ვთქვით პარალელიზმია, რომელიც process რამოდენიმე thread ებად დაანაწილებს. მაგალითად შეგვიძლია browser ი ავიღოთ, რომელიც ოპერაციულ სისტემაში process ად არის გაშვებული, მაგრამ თითოეული Tab ი შეიძლება იყოს სხვადასხვა thread ი. რა თქმა უნდა ზოგადად ვსაუბრობ, რეალობაში შეიძლება ყველა browser ი, სხვადასხვანაირად იქცეოდეს და სულაც არ იყენებდეს thread ებს და ყველა TAB ი ცალკეულად გაშვებული child პროცესი იყოს.
ფუნდამენტალური იდეა კი რა თქმა უნდა ის არის, რომ პროცესად გაშვებული პროგრამის ინსტრუქციები მუდამ ერთმანეთს არ ელოდებოდნენ თავიანთი რიგისთვის და ერთ პროგრამას შეეძლოს პარალელურად ერთზე მეტი ოპერაციის შესრულება.
მაგალითად
- დაუკავშირდეს web service ს პარალალურად, სანამ user ი იყენებს აპლიკაციის სხვა ნაწიელბს.
- წაიკითხოს მონაცემები ლოკალური ბაზიდან ან ჩაწეროს პარალელურად.
- შეასრულოს რაიმე მძიმე გამოთვლით ოპერაცია პარალელურიად.
- შეასრულოს Input / Output ოპერაციები დისკზე პარალელურად.
- პარალელურ რეჟიმში დაუკავშირდეს რამოდენიმე web service ს და არა რიგ-რიგობით.
კიდევ სხვა მრავალი მაგალითი შეგვიძლია მოვიყვანოთ thread ებისთვის, თუმცა ვფიქრობ საკმარისია.
და მაინც რა განსხვავებაა Thread სა და Process შორის ?
ფუნდამენტალური სხვაობა არის, რომ thread ებს, რომლებიც ერთ პროცესში არიან აქვთ ერთი shared memory space ი, ხოლო პროცესებს როგორც ზევით ვახსენე აქვთ სხვადასხვა. Thread ები არ არიან დამოუკიდებლები, როგორც პროცესები. Thread ები იზიარებენ სხვა thread ებთან კოდის სექციებს, მონაცემებს და OS ის რესურსებს. მაგრამ thread ებს ასევე აქვთ საკუთარი program counter(PC), რეგისტრების სეტი და stack space ი.
რა არის program counter ი ან რეგისტრები?
იმისთვის, რომ ინსტრუქციები გაიცვალოს პარალელურ thread ებს შორის, გვჭირდება რომ execution state ი შევინახოთ სადმე. state ის შენახვა კი ზუსტად program counter ებში და რეგისტრებში ხდება. PC გვეუბნება თუ რომელი ბრძანება უნდა შესრულდეს thread ების დამერჯვის შემდეგ პირველი და საიდან უნდა გავაგრძელოთ სვლა, ხოლო CPU ს რეგისტრები ინახავენ სხვადასხვა არგუმენტებს კონკრეტული execution ისთვის.
Thread ებს რამოდენიმე უპირატესობაც კი აქვტProcess ებთან შედარებით
- სწრაფი Context switch ი. როგორც ზევით ვახსენეთ Scheduler ს პროცესებთან სამუშაოდ ჭირდება, რომ გამოიყენოს CPU ს time-sharing ი, რაც ლოგიკურად მეტ overhead ს აჩენს. ხოლო thread ების შემთხვევაში კონტექსტების შეცვლა ბევრად უფრო მარტივია და სწრაფი.
- ეფექტური გამოყენება სხვადასხვა პროცესორიან სისტემებში. თუ ჩვენ გვაქვს სხვადასხვა thread ი ერთ პროცესში, ჩვენ შეგვიძლია thread ები სხვადასხვა პროცესორზე გავუშვათ, რაც ლოგიკურად პროცესის სწრაფ execution ს მოგვცემს.
- რესურსების გაზიარება ბევრად უფრო სწრაფია და მარტივი thread ებს შორის და არ გვჭირდება რომ გამოვიყენოთ IPC ი.
Thread ები შეგვიძლია 2 ნაწილად დავყოთ
- User level thread
- Kernel level thread
User level thread ი მაღალი დონის აბსტრაქციიდან იქმნება, რაშიც კერნელი არ ერევა. ამ thread ების მენეჯმენტიც high-level იდან ხდება, თუმცა მაინც ჭირდება kernel ის sys-call ი (system call). User level thread ები ბევრად უფრო სწრაფები არიან და მათი management იც მარტივია. Context-switching ი კი ბევრად სწრაფი. ყველაზე მთავარი კი ის არის, რომ მათი გაშვება ნებისმიერ ოპერაციულ სისტემაზე შეიძლება ვირტუალური გარემოს მეშვეობით.
Kernel level thread ებს მთლიანად OS ამენეჯმენტებს. Scheduling იც სხვა დანარჩენიც kernel ის პასუხისმგებლობაა. თუმცა User level thread ებთან განსხვავებით ისინი ბევრად ნელები არიან, management overhead ის გამო. Context switching ი ბევრად უფრო მეტ საფეხურს მოიცავს ვიდრე უბრალოდ სტეიტის შენახვა სხვადასხვა რეგისტრში და PC ში.
მაგალითად, თითქმის ყველა mainstream თანამედროვე ენას აქვს thread ებთან სამუშაოდ თავიანთი გარემო, აბსტრაქცია.
- C# Tasks
- Swift DispatchQueue, Tasks
- Kotlin coroutines
- Go goroutines
თითქმის ყველა ზემოთ ხსენებული (თუ არ ვცდები), იყენებენ Windows ის ენაზე green-thread ებს, ხოლო UNIX ის ენაზე user level thread ებს, და ქვედა დონეზე წყვეტენ როდის უნდა შეიქმნას kernel level thread ი და როდის user level ი, ყოველდღიურ დეველოპმენტში ჩვენ დეველოპერებს ამაზე ფიქრი არ გვიწევს და რეალურად ყოველდღიური რუტინული დავალებები არ ქმნის საჭიროებას, რომ გამოვიყენოთ kernel level thread ები, თუ რაღაც სპეციფიური მიზეზი არ გაგვაჩია.
თუმცა წოტა თემას, რომ გადავუხვიოთ ასევე არსებობს ენები, რომლებიც Multithreading ს საერთოდ არ ასაპორტებენ. ან შეიძლება გააჩნდეთ Multithreading ის მოდელი, მაგრამ არა პარალელიზმის.
ასეთი ენები ძირითადად Event-loop ს იყენებენ, თუმცა ამის შესახებ მოგვიანებით.
მემგონი საკმაოდ მსუყე სტატია გამოვიდა, თუ ზევით აღწერილი თემები და საკითხები გაინტერესებთ, აქვე გაგიზიარებთ რესურსებს რომლებსაც ბოლო თვეების განმავლობაში ვიყენებ.
- CMU ს კურსი Introduction to computer systems ეს კურსი ჩემმა ძალიან ჭვკიანმა მეგობარმა მირჩია რამოდენიმე თვის წინ და თამამად შემიძლია ვთქვა, რომ ერთ-ერთი ყველაზე ძნელი და ამავდროულად საინტერესო გზა არის იმისთვის, რომ გაიცნო როგორ მუშაობს სამყარო შენს ქვემოთ, იმისთვის რომ შენ, შენი საქმე ყოველდღიურად უმტკივნეულოდ შეასრულო.
- Dinosour book ამ წიგნის რეკომენდაცია Quora ზე Robert Love ის გან ვნახე, რომელიც ასევე Linux kernel development წიგნის ავტორია, იყო core engineer ი კერნელში და შემდეგ Director of engineering ი Google ში.
- Bible of Operating systems კლასიკა, მხოლოდ 6$ ად.
- Vegard wiki — ეს ბლოგი მე და ჩემმა მეგობარმა აღმოვაჩინეთ, როდესაც kernel ის source ში ვდიგერობდით. საკუთარი ვიკიპედია აქვს თითქმის ყველა Computer science ის თემაზე, ნამდვილი საჩუქარია.
ჩემი აზრით აგნოსტიკური მიდგომა ჩვენს სფეროში, აორმაგებს და ბევრად უფრო პროდუქტიულს გვხვდის ჩვენს საკუთარ domain ში. მნიშვნელობა არ აქვს ეს იქნება Web, Mobile თუ სხვა. System ური მიდგომა და ცოდნა, მჯერა რომ ბევრად უფრო კარგ დეველოპერებად გვაყალიბებს.
მადლობა.